
Monitoring VS APM
Quels outils pour vous accompagner dans vos tests ?
Pourquoi le monitoring est utile après un test de charge ?
Les tests de charge permettent de pousser un système à ses limites pour évaluer ses performances et sa stabilité sous contrainte. Cependant, une fois ces tests réalisés, la collecte de données seule n’est pas suffisante. C’est ici que le monitoring entre en jeu, offrant une analyse approfondie des résultats et permettant de transformer des chiffres bruts en informations exploitables. Le monitoring post-test peut répondre à ces questions :
- Quels sont les goulots d’étranglement identifiés ?
- Quelles ressources étaient sous-utilisées ou saturées ?
- Quels éléments ont contribué à des temps de réponse élevés ou à des erreurs systèmes ?
Le monitoring ne se limite pas aux tests de charge ponctuels. Il s’inscrit dans une stratégie de surveillance continue, garantissant que les performances restent conformes aux attentes, même en production. Deux grandes approches se distinguent pour cette tâche : les solutions de monitoring basées sur Grafana et Prometheus, et les outils d’APM (Application Performance Monitoring) comme Dynatrace, New Relic ou Datadog. Ces solutions, bien que complémentaires, répondent à des besoins différents.
Grafana + Prometheus : La puissance du monitoring open source
Prometheus collecte les métriques des systèmes (CPU, mémoire, latence, etc.) à intervalles réguliers via des endpoints exposés. Grafana, quant à lui, transforme ces métriques en tableaux de bord visuels et interactifs. Ensemble, ces outils open source permettent de créer une solution de monitoring flexible et personnalisable.
Avantages :
- Solution économique, sans frais de licence.
- Grande flexibilité dans la configuration des tableaux de bord et des alertes.
- Adapté pour monitorer les tests de charge, notamment avec des outils comme K6, Locust ou JMeter.
Limites :
- Configuration technique plus complexe, exigeant des compétences en administration système.
- Absence de certaines fonctionnalités avancées comme la traçabilité distribuée.
- Analyse limitée aux métriques systèmes, sans analyse approfondie des transactions utilisateur.
Quand les utiliser ?
- Si vous avez une architecture relativement simple (serveurs ou APIs isolés).
- Pour monitorer des tests de charge ponctuels ou réguliers.
- Si vous recherchez une solution économique et open source.
APM : Une analyse avancée pour les systèmes complexes
Les outils d’APM vont au-delà des métriques systèmes. Ils permettent une surveillance approfondie des performances des applications, en mettant l’accent sur les transactions utilisateur, les dépendances entre services, et les anomalies potentielles.
Avantages :
- Traçabilité distribuée : Identification des goulots d’étranglement sur tout le parcours d’une requête.
- Surveillance proactive : Détection d’anomalies grâce à l’IA et machine learning.
- Intégration facile avec des écosystèmes complexes (cloud, microservices, conteneurs).
Limites :
- Coût élevé, souvent facturé par hôte ou par transaction.
- Moins adapté pour les environnements simples ou à petit budget.
Quand les utiliser ?
- Si votre architecture comprend des microservices ou des conteneurs.
- Pour les applications critiques où une défaillance pourrait impacter directement les utilisateurs.
- Lorsque vous avez besoin d’une solution « clé en main » avec peu de configuration manuelle.
Grafana + Prometheus | Dynatrace, New Relic, Datadog (APM) | |
Type d’outil | Monitoring et visualisation de métriques | Monitoring avancé et gestion des performances applicatives |
Cas d’usage principal | Collecte et affichage de métriques système (CPU, RAM, erreurs, etc.) | Analyse des transactions utilisateur, traces distribuées, dépendances |
Traçabilité distribuée | Non pris en charge nativement (nécessite Jaeger ou Zipkin) | Intégré, avec suivi des requêtes de bout en bout |
Alertes et anomalies | Seuils manuels dans Prometheus | Alertes automatiques basées sur l’IA |
Scalabilité | Dépend de l’infrastructure déployée | Haute scalabilité pour des systèmes complexes |
Coût | Open source (coûts d’infrastructure et maintenance) | Payant (coûts par hôte ou transaction monitorée) |
Intégration avec Prometheus
Reprenons l’exemple de Locust et intégrons les outils de monitoring Grafana et Prometheus pour visualiser et analyser les données de performance en temps réel, de manière plus détaillée et centralisée. Cette approche est très utile pour les équipes souhaitant un suivi approfondi et historique des tests de charge, souvent intégré dans un système de surveillance global.
Pour cela, il faut installer la bibliothèque :
pip install prometheus-client
Puis, ajoutez un serveur de métriques basé sur prometheus-client dans votre script Locust :
from locust import HttpUser, task, between, events
from prometheus_client import start_http_server, Summary, Counter
REQUEST_LATENCY = Summary(‘http_request_latency_seconds’, ‘Time spent processing HTTP requests’)
REQUEST_COUNT = Counter(‘http_request_count’, ‘Number of HTTP requests processed’, [‘endpoint’])
@events.init.add_listener
def start_metrics_server(environment, **kwargs):
start_http_server(9100)
class JSONPlaceholderUser(HttpUser):
host = « https://jsonplaceholder.typicode.com »
wait_time = between(1, 3)
@task(3)
@REQUEST_LATENCY.time()
def get_posts(self):
response = self.client.get(« /posts »)
REQUEST_COUNT.labels(endpoint= »/posts »).inc()
if response.status_code != 200:
print(f »Failed request to /posts with status {response.status_code} »)
@task(2)
@REQUEST_LATENCY.time()
def get_comments(self):
response = self.client.get(« /comments »)
REQUEST_COUNT.labels(endpoint= »/comments »).inc()
if response.status_code != 200:
print(f »Failed request to /comments with status {response.status_code} »)
@task(1)
@REQUEST_LATENCY.time()
def get_users(self):
response = self.client.get(« /users »)
REQUEST_COUNT.labels(endpoint= »/users »).inc()
if response.status_code != 200:
print(f »Failed request to /users with status {response.status_code} »)
Configurer Prometheus pour collecter les données Locust :
- Dans le fichier de configuration de Prometheus (prometheus.yml), ajoutez une section pour surveiller l’endpoint Locust.
scrape_configs:
– job_name: « locust »
metrics_path: « /metrics »
static_configs:
– targets: [« localhost:9100 »]
Cette configuration dit à Prometheus de scruter l’endpoint /metrics de Locust à intervalles réguliers. Les données collectées incluent des informations sur les temps de réponse, les taux d’échec, les requêtes par seconde, et d’autres métriques de performance.
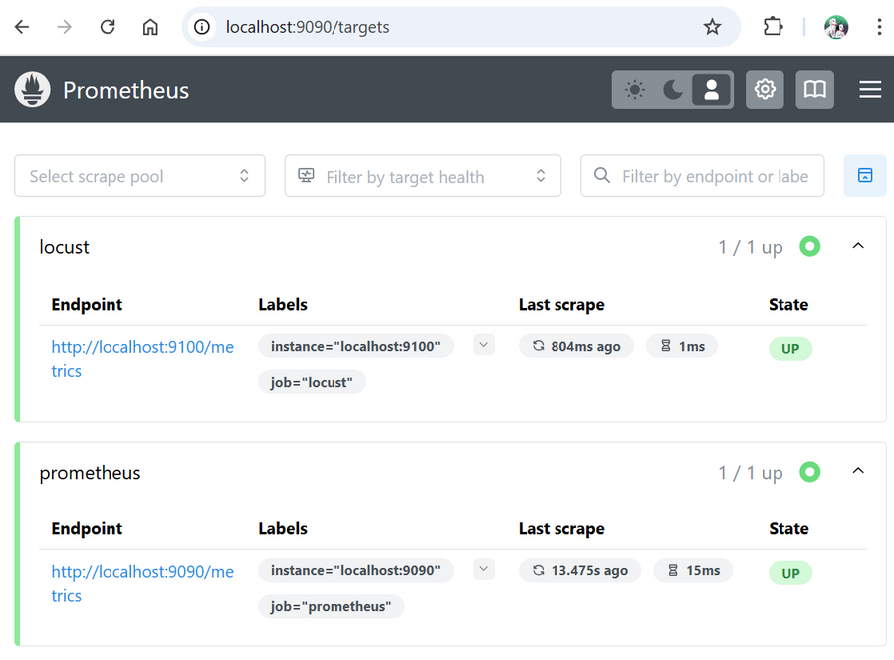
Maintenant, dans localhost:9090/targets, vous devez voir le endpoint de locust et celui de prometheus :
Puis exécutez le script avec :
locust -f mon_script.py –host https://jsonplaceholder.typicode.com –headless -u 1 -r 10 –run-time 10s
- –headless : Cette option exécute Locust en mode sans interface graphique. Cela signifie que vous n’avez pas accès à l’interface web de Locust, et que toutes les informations de suivi seront affichées directement dans le terminal. Ce mode est souvent utilisé pour des tests automatisés, comme dans un pipeline CI/CD.
- -u 100 : L’option -u permet de définir le nombre total d’utilisateurs simulés (ou « virtual users ») qui participeront au test. Dans cet exemple, Locust simulera 100 utilisateurs simultanés au maximum.
- -r 10 : Cette option (-r) définit le taux de montée en charge (ou « spawn rate »), soit le nombre d’utilisateurs qui seront ajoutés chaque seconde jusqu’à atteindre le total défini avec -u. Ici, 1 utilisateur est ajouté chaque seconde, donc il faudra environ 10 secondes pour atteindre les 10 utilisateurs spécifiés.
- –run-time 10s : Cette option fixe la durée totale du test. Ici, le test est configuré pour s’exécuter pendant 10 secondes. Vous pouvez spécifier la durée en secondes (s), minutes (m), ou heures (h). Par exemple, –run-time 30m pour 30 minites ou –run-time 1h pour une heure.
Puis dans Graph, tapez http_request_count_total, vous devriez avoir un graphique :
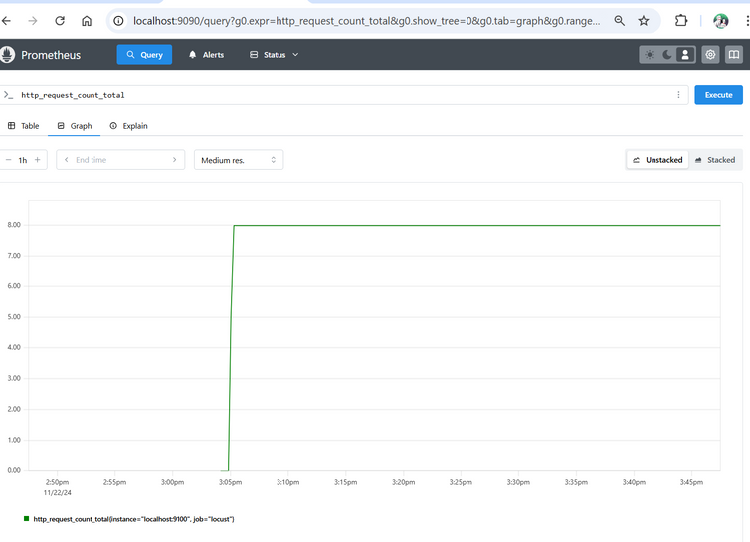
Vous êtes prêts pour créer un dashboard Grafana !
Intégration avec GRAFANA
Pour installer Grafana en local, en premier, il faut ajouter le dépôt officiel Grafana et de la clé GPG manquante :
wget -q -O – https://packages.grafana.com/gpg.key | sudo gpg –dearmor -o /usr/share/keyrings/grafana-archive-keyring.gpg
echo « deb [signed-by=/usr/share/keyrings/grafana-archive-keyring.gpg] https://packages.grafana.com/oss/deb stable main » | sudo tee /etc/apt/sources.list.d/grafana.list > /dev/null
Puis, mettez à jour les listes de paquets et installez Grafana :
sudo apt-get update
sudo apt-get install grafana
Et enfin, démarrez Grafana avec des permissions root (si nécessaire) :
sudo grafana-server –homepath=/usr/share/grafana
Vous pouvez ainsi ouvrir Grafana :
Le mot de passe et nom d’utilisateur est admin
Intégration avec GRAFANA
Plusieurs solutions s’offrent à vous.
Après avoir configurer Prometheus, vous pouvez utiliser Grafana pour les visualiser.
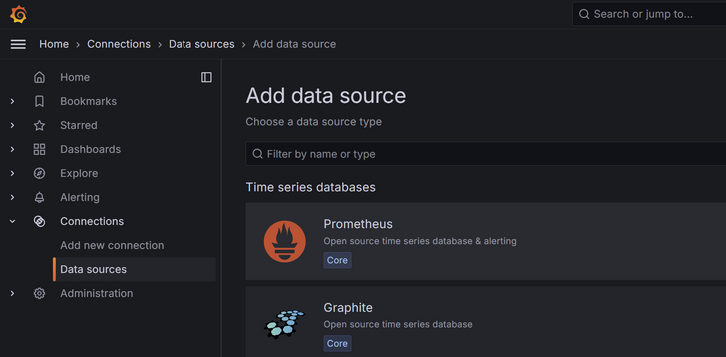
Pour cela, ajoutez Prometheus comme source de données dans Grafana :
- Dans Grafana, allez dans Configuration > Data Sources, puis sélectionnez Prometheus.
- Entrez l’URL de votre serveur Prometheus (ici, http://localhost:9090) et enregistrez la source de données.
- Ensuite, vous pouvez créer des tableaux de bord personnalisés dans Grafana pour visualiser les métriques spécifiques de Locust. Grafana propose de nombreux types de graphiques (courbes, jauges, histogrammes) pour représenter les données de manière claire.
Créer un dashboard et ajouter un panel :
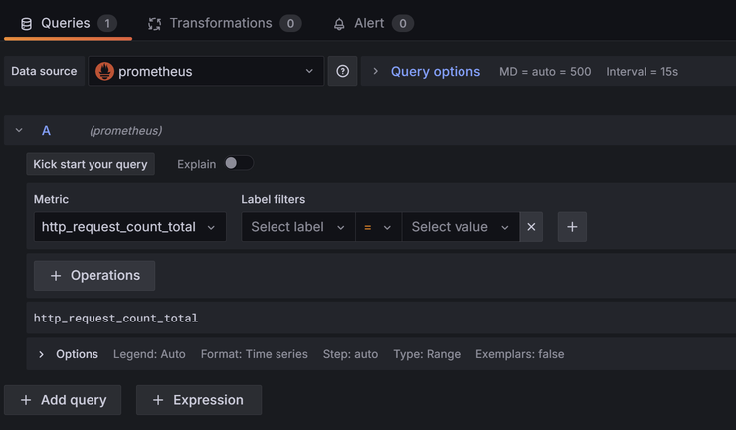
Ajouter Prometheus en data source, Puis ajouter une métrique, par exemple, http_request_count_total.
Sauvegardez, vous aurez un graphique ressemblant à :
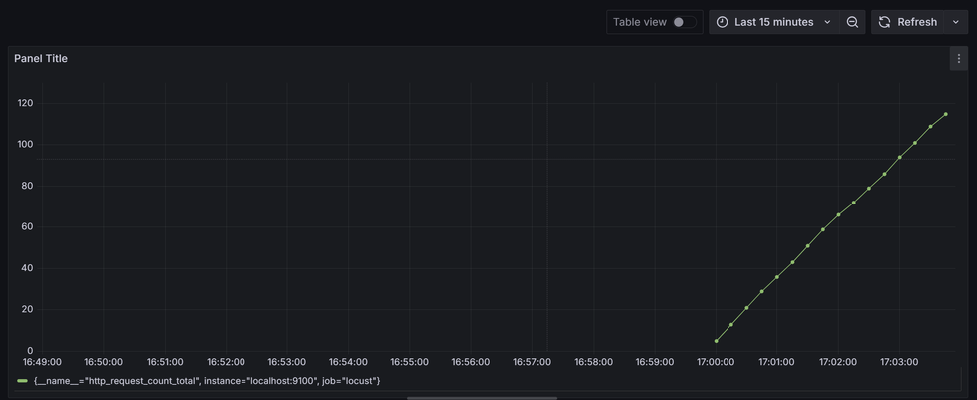
Vous pouvez ainsi créer votre dashboard personnalisé.
La seconde solution est d’importer un dashboard existant :
- Pour simplifier, vous pouvez trouver des dashboards préconçus dans la Galerie de Dashboards Grafana. Par exemple, certains dashboards sont déjà configurés pour les tests de charge Locust et les métriques exposées par Prometheus. Vous pouvez surveiller :
- Le nombre d’utilisateurs actifs et leur montée en charge.
- Les temps de réponse par percentile (médiane, 90e, 95e, etc.).
- Le nombre de requêtes par seconde (RPS) et les taux d’échec.
- L’utilisation des ressources système si Prometheus collecte également des données de monitoring de votre infrastructure.
- Vous pouvez également configurer des alertes dans Grafana, par exemple, pour être informé si le taux d’échec dépasse un certain seuil ou si le temps de réponse devient trop élevé.
Vous pouvez trouver la liste des dashboards à cette URL : https://grafana.com/grafana/dashboards/?search=locust
Nous prenons pour exemple Locust for Prometheus. Cliquez sur Copy to clipboard. Puis importer un nouveau dashboard :
Voici le résultat de deux campagnes de test :
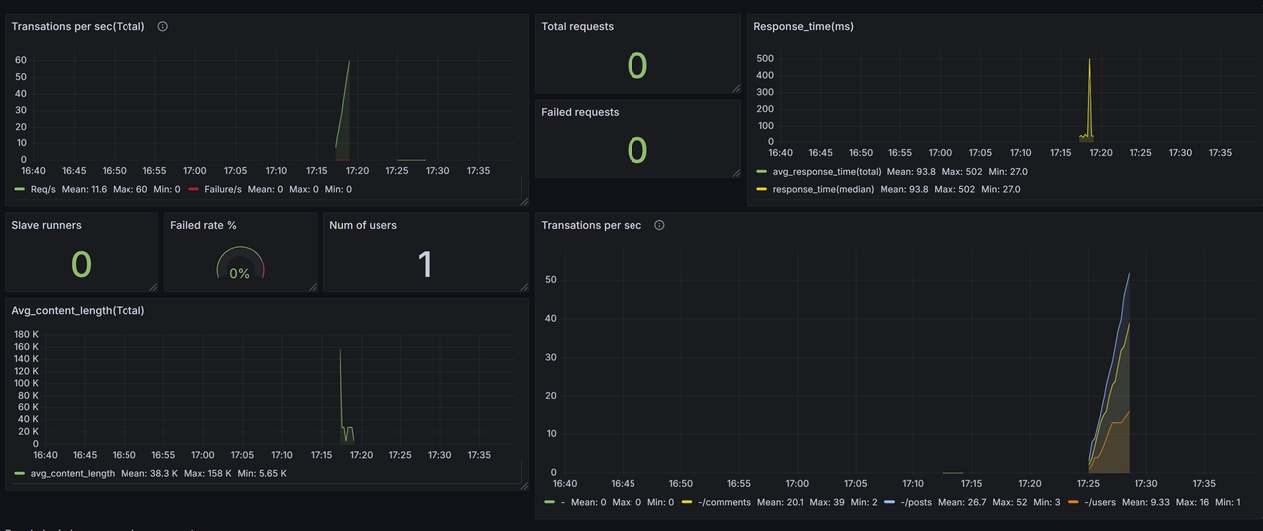
Nous pouvons voir que :
- Stabilité : Le système semble stable avec 1 utilisateur, sans échecs, et des temps de réponse moyens rapides.
- Temps de réponse :
- La majorité des requêtes sont traitées rapidement (93 ms en moyenne).
- Un pic de 502 ms peut nécessiter une investigation plus approfondie (endpoint concerné ou moment précis).
- Charge utilisateur : Ce test montre une faible charge, adaptée pour vérifier la base. Augmenter progressivement les utilisateurs permettra de valider la capacité de montée en charge.
- Données cohérentes :
- Les tailles de réponse sont alignées avec les endpoints JSON.
- Les proportions entre les endpoints sont respectées dans les RPS.
Intégration avec GRAFANA
Sinon, vous pouvez utiliser Grafana sans Prometheus. Grafana est compatible avec plusieurs sources de données, et il est tout à fait possible de l’utiliser pour visualiser des données à partir de fichiers CSV ou d’autres sources, bien que cela demande quelques étapes de configuration supplémentaires.
Grafana ne prend pas en charge les fichiers CSV nativement, mais il existe des plugins qui permettent de les utiliser comme source de données.
Un plugin populaire pour cela est « CSV Plugin for Grafana » (ou parfois appelé Infinity Plugin). Vous pouvez l’installer via la commande suivante (nécessite les droits d’administrateur sur le serveur où Grafana est installé) :
grafana-cli plugins install grafana-infinity-datasource
Puis redémarrer avec :
sudo systemctl restart grafana-server
Ajouter une source de données CSV dans Grafana
- Une fois le plugin installé et Grafana redémarré, allez dans Configuration > Data Sources dans l’interface de Grafana, puis cliquez sur Add data source.
- Recherchez et sélectionnez Infinity (ou CSV plugin selon le plugin utilisé).
- Configurez le plugin pour qu’il puisse lire des fichiers CSV. Selon le plugin, vous aurez la possibilité soit d’indiquer un chemin d’accès à un fichier local, soit de spécifier une URL pour un fichier CSV hébergé (par exemple, sur un serveur HTTP).
Charger les données CSV :
- Configurez le chemin du fichier CSV ou l’URL directe vers le fichier CSV. Assurez-vous que le fichier est accessible par le serveur où Grafana est installé si vous utilisez un chemin local.
- Le plugin vous permet de spécifier des paramètres comme le séparateur de colonnes (, pour CSV, ; pour certains fichiers), le format de date, et d’autres options pour parser le contenu correctement.
Créer des dashboards et graphiques :
- Dans le panneau de configuration des graphiques, sélectionnez la source de données CSV et configurez les visualisations en fonction des colonnes de votre fichier CSV.
- Par exemple, si votre fichier CSV contient des colonnes « timestamp », « response_time », et « RPS », vous pouvez utiliser ces champs pour créer des graphiques de série temporelle, des jauges, ou des histogrammes.
APM : Dynatrace
Dynatrace est une plateforme avancée de monitoring et d’observabilité, souvent reconnue pour ses capacités d’analyse de performance en temps réel et son intelligence artificielle pour détecter automatiquement les anomalies. Bien que son cœur d’activité soit le monitoring, Dynatrace offre des fonctionnalités puissantes pour les tests de charge, en particulier lorsqu’elles sont combinées à d’autres outils de test de performance.
Dynatrace ne remplace pas directement les outils de test de charge comme LoadRunner ou NeoLoad. Cependant, il complète ces solutions en offrant une visibilité approfondie sur les performances systèmes et les comportements applicatifs pendant les tests. Voici comment il fonctionne :
- Surveillance des métriques clés : Dynatrace collecte et analyse en temps réel les métriques de performance (temps de réponse, utilisation des ressources, transactions, etc.) pendant un test de charge.
- Corrélation des données : La plateforme associe les données de performance aux logs, aux traces distribuées et aux événements systèmes pour fournir une vue unifiée de la santé des systèmes.
- Anomalies automatisées : Grâce à son IA, Dynatrace identifie automatiquement les goulets d’étranglement, les anomalies de performance et les dépendances critiques qui peuvent limiter la scalabilité.
- Rapports détaillés : Les rapports Dynatrace mettent en évidence les problèmes rencontrés, tels que les problèmes de base de données, les limitations de CPU/mémoire, ou les délais liés aux appels API.
Avantages
- Observabilité approfondie : Contrairement aux outils traditionnels, Dynatrace fournit une vue détaillée sur les microservices, les containers, et les environnements cloud.
- Détection prédictive des anomalies : L’IA de Dynatrace anticipe les problèmes potentiels avant qu’ils ne deviennent critiques.
- Automatisation : Les tests peuvent être intégrés aux workflows CI/CD pour des tests de performance continus.
- Corrélation avec l’expérience utilisateur : Dynatrace relie les performances systèmes aux impacts sur les utilisateurs finaux, aidant ainsi à prioriser les résolutions.
Limitations
- Coût : Dynatrace est une solution premium, ce qui peut représenter un investissement important pour les petites entreprises.
- Dépendance à d’autres outils : Il ne remplace pas les outils de test de charge comme JMeter ou LoadRunner ; il les complète.
- Configuration initiale : Bien que la plateforme soit intuitive, une configuration initiale minutieuse est nécessaire pour des résultats optimaux.
Cas d’utilisation
- Tests pré-déploiement : S’assurer que l’application peut gérer les charges prévues dans un environnement de production.
- Optimisation cloud : Identifier les goulots d’étranglement dans les architectures cloud-natives.
- Validation des microservices : Tester les microservices individuellement pour vérifier leur performance et leur scalabilité.
- Surveillance continue : Effectuer des tests réguliers dans le cadre des pipelines CI/CD pour garantir la stabilité.
Mise en oeuvre avec K6 : Visualisation des résultats dans Dynatrace
Dynatrace peut être intégré avec des outils comme K6 pour surveiller en temps réel les métriques de performance.
Voici les étapes pour configurer cette intégration et visualiser les résultats dans un tableau de bord Dynatrace.
Préparation de l’environnement
Utilisez l’outil xk6 pour ajouter l’extension Dynatrace à K6 :
xk6 build –with github.com/Dynatrace/xk6-output-dynatrace@latest
Cela génère un fichier k6.exe capable d’envoyer des métriques directement à Dynatrace.
Avant, vous aurez peut-être besoin d’installer Go :
- Rendez-vous sur le site officiel : https://go.dev/dl/
- Téléchargez la version compatible avec votre système d’exploitation
- Suivez les instructions de l’installateur pour terminer l’installation
Puis créez votre compte Dynatrace sur : https://www.dynatrace.com/
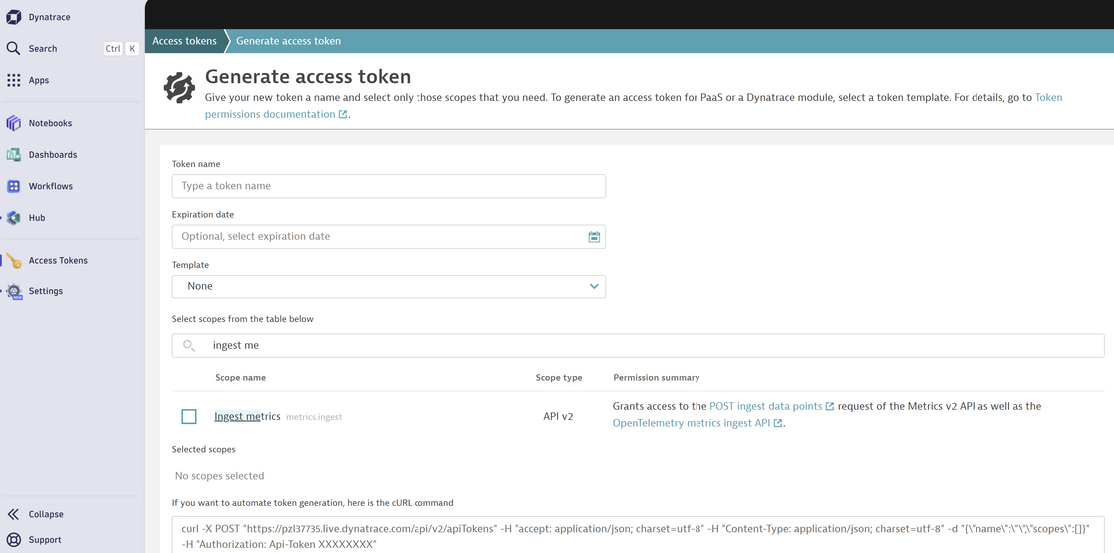
Ensuite, créez votre token, Rendez-vous dans Settings > Access Tokens et générez un token avec au minimum la permission “Ingest metrics”
Définissez les variables d’environnement
K6_DYNATRACE_URL= »https://<environmentid>.live.dynatrace.com »
K6_DYNATRACE_APITOKEN= »<api-token> »
L’api token est le token que vous avez créer précédemment. Vous trouverez l’environnement id en bas sous votre nom :

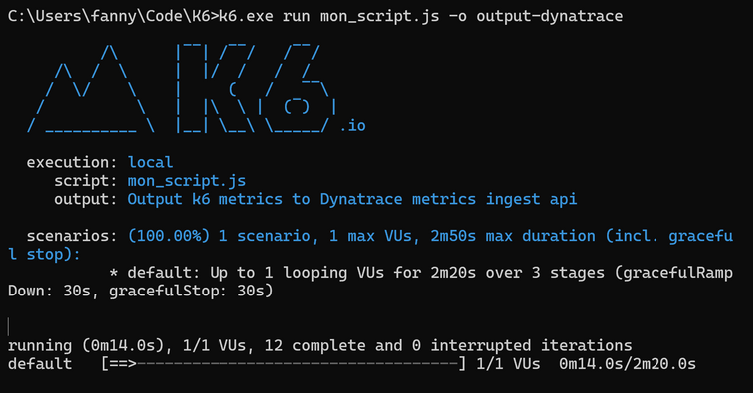
Lancer le test K6 avec l’extension Dynatrace
k6.exe run mon_script.js -o output-dynatrace
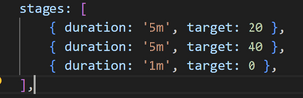
Reprenons l’exemple page 25 du script K6, et adaptez les durations pour l’exécuter plus de 20 min :
Après 20 min d’exécutions :
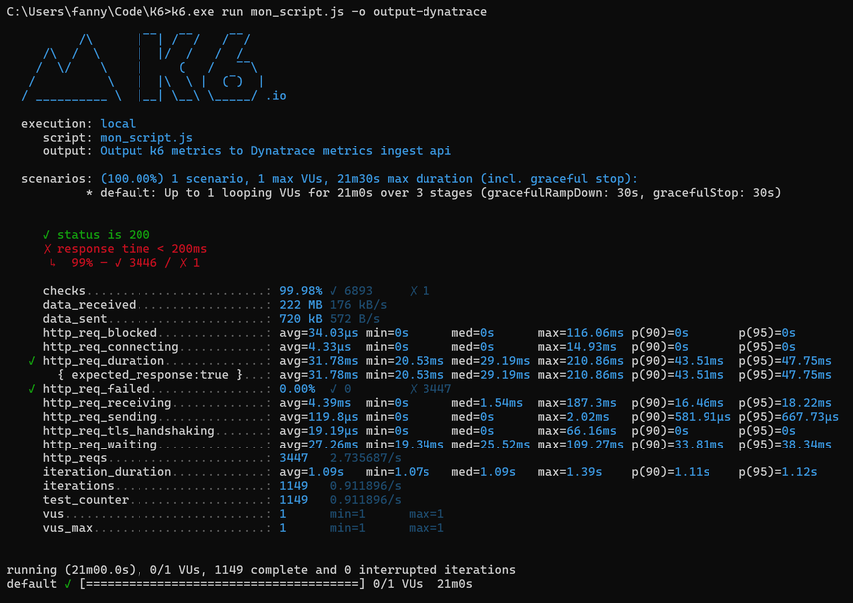
vous pouvez donc vérifiez vos métriques dans Dynatrace dans la section metrics :
 Si vous n’avez pas de metrics, vous pouvez tester votre connexion :
Si vous n’avez pas de metrics, vous pouvez tester votre connexion :
curl -X POST « https://<environmentid>.live.dynatrace.com/api/v2/metrics/ingest » -H « Authorization: Api-Token <votre-token-api> » -H « Content-Type: text/plain » –data « custom.metric.test,environment=test 1 »
Si vous avez 401 comme reponse, revoyez vos variables d’environnements
vous pouvez donc vérifiez vos métriques dans Dynatrace dans la section metrics :
Vous pouvez créer un dashboard personnalisé en cliquant sur “Create Chart” puis sur Pin to dashboard en spécifiant le nom du dashboard que vous voulez créer :
Vous pouvez utiliser les différentes informations :
Pour les requetes HTTP :
http_reqs : Nombre total de requêtes HTTP.
http_req_duration : Durée totale des requêtes HTTP (y compris le temps de réception et d’attente).
http_req_waiting : Temps d’attente pour la réponse du serveur.
http_req_connecting : Temps pour établir une connexion TCP.
http_req_tls_handshaking : Temps pour établir une connexion TLS/SSL.
http_req_sending : Temps pour envoyer la requête HTTP.
http_req_receiving : Temps pour recevoir la réponse HTTP.
http_req_failed : Taux d’échec des requêtes HTTP (en pourcentage).
Utilisation des ressources :
vus : Nombre d’utilisateurs virtuels actifs (Virtual Users).
vus_max : Nombre maximal d’utilisateurs virtuels pendant le test.
iterations : Nombre total d’itérations complétées (chaque utilisateur exécute une itération du script).
Performance et latence :
iteration_duration : Temps moyen pour terminer une itération complète (par utilisateur).
checks : Pourcentage de contrôles réussis ou échoués dans le test.
Données transmises :
data_sent : Volume total de données envoyées (en octets).
data_received : Volume total de données reçues (en octets).
Import de dashboard K6
Sinon, vous pouvez importer des dashboards existants. Gardons l’exemple de K6 et rendez vous sur le github :
https://github.com/dynatrace-perfclinics/dynatrace-getting-started/blob/main/dashboards/k6/Grafana%20k6%20Dashboard.json
Téléchargez le dashboard et importez le dans dynatrace en cliquant sur upload :
Le résultat du test que nous avons fait est alors :
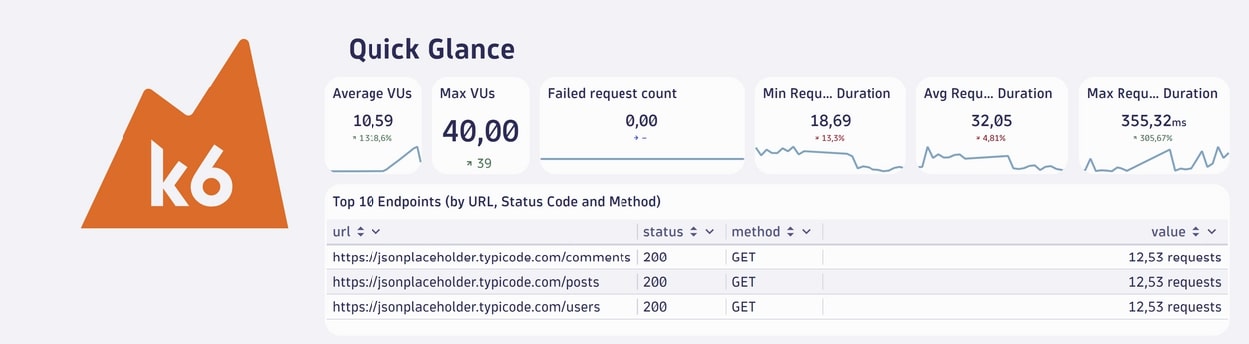
Section « Quick Glance » (Aperçu rapide)
- Average VUs (Virtual Users) :
- Moyenne des utilisateurs virtuels (VUs) actifs pendant le test.
- Dans notre cas, 10,59 utilisateurs virtuels étaient actifs en moyenne.
- La flèche indique une augmentation de 1318,6 %, ce qui signifie une forte montée en charge par rapport à la session précédente qui ne chargeait que d’une minute.
- Max VUs (Virtual Users) :
- Nombre maximum d’utilisateurs virtuels simultanés au cours du test.
- Ici, 40,00 utilisateurs actifs ont été atteints.
- Failed request count :
- Nombre total de requêtes HTTP ayant échoué.
- Dans notre test, aucune requête n’a échoué (la barre reste vide).
- Min Request Duration :
- Temps de réponse minimum (en millisecondes) parmi toutes les requêtes HTTP.
- Ici, la requête la plus rapide a pris 18,69 ms.
- La flèche rouge (-13,3 %) indique une amélioration (réduction du temps minimum par rapport à la session précédente).
- Avg Request Duration :
- Temps moyen de réponse des requêtes HTTP.
- Les requêtes ont pris en moyenne 32,05 ms pour obtenir une réponse.
- Une augmentation de 4,81 % indique une légère dégradation de la performance moyenne par rapport au test précédent.
- Max Request Duration :
- Temps de réponse maximum pour les requêtes HTTP.
- La requête la plus lente a pris 355,32 ms.
- Une augmentation de 305,67 % indique qu’une ou plusieurs requêtes ont pris beaucoup plus de temps qu’avant, ce qui peut signaler un problème ponctuel ou un goulot d’étranglement.
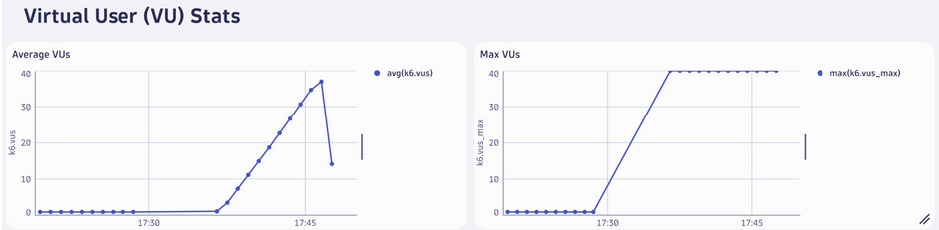
Average VUs (Utilisateurs Virtuels Moyens)
- Le graphique montre la moyenne des utilisateurs virtuels actifs (VUs) à différents moments du test.
- Interprétation :
- Une montée progressive est visible jusqu’à atteindre environ 40 utilisateurs actifs, avant de diminuer à la fin du test.
- Cela correspond aux étapes de montée en charge définies dans notre script
Max VUs (Utilisateurs Virtuels Maximum)
- Le graphique montre le nombre maximal d’utilisateurs simultanés atteints à chaque instant.
- Interprétation :
- Vous atteignez un maximum de 40 utilisateurs simultanés à la fin de la montée en charge, ce qui semble stable avant la phase de descente.
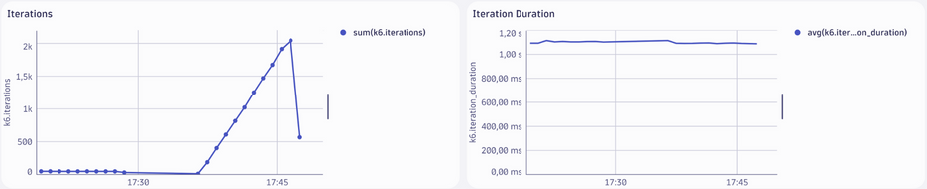
Itérations
- Le graphique affiche le nombre total d’itérations complétées au fil du temps.
- Interprétation :
- Une augmentation régulière est observée, correspondant à l’accélération de la montée en charge (plus d’utilisateurs exécutant simultanément des itérations).
- Le nombre d’itérations décroît lorsque les utilisateurs virtuels diminuent à la fin du test.
- Ce total est directement lié aux utilisateurs actifs et à la durée du test.
- Utilisation :
Confirmez si le nombre d’itérations correspond aux attentes.
Iteration Duration (Durée des Itérations)
- Le graphique montre la durée moyenne d’une itération (en secondes ou millisecondes).
- Interprétation :
- Les itérations prennent en moyenne 1,2 secondes, ce qui reste constant tout au long du test.
- Cela indique que le système semble capable de gérer la charge imposée par les utilisateurs, sans augmentation significative des temps d’exécution.
- Utilisation :
- Une augmentation soudaine ou progressive de la durée des itérations pourrait signaler un goulot d’étranglement ou une saturation des ressources.
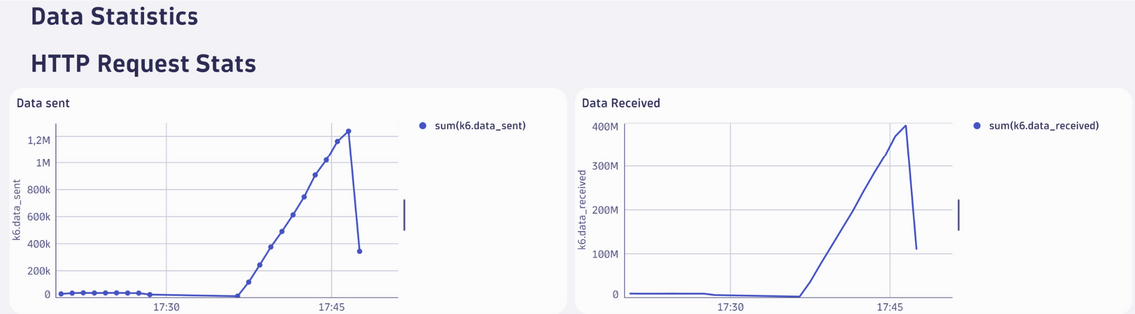
Data Sent (Données envoyées)
- Le graphique montre le volume total de données envoyées par les utilisateurs virtuels (VUs) tout au long du test.
- Interprétation :
- Une augmentation progressive est observée au fur et à mesure que le nombre d’utilisateurs actifs augmente.
- À son pic, environ 1,2 Mo de données ont été envoyées.
- La diminution à la fin correspond à la phase de réduction des utilisateurs virtuels.
- Utilisation :
Permet de vérifier si le volume des données envoyées reste conforme à ce qui est attendu pour les tests de charge (par exemple, tailles des requêtes HTTP).
Data Received (Données reçues)
- Le graphique montre le volume total de données reçues en réponse aux requêtes HTTP.
- Interprétation :
- Le volume de données reçues augmente proportionnellement au nombre d’utilisateurs virtuels actifs et atteint environ 400 Mo au pic.
- Une forte diminution est visible à la fin, reflétant la réduction des utilisateurs actifs.
- Utilisation :
- Confirmez si le volume de données reçues correspond à la taille attendue des réponses serveur.
- Une diminution ou des anomalies pourraient indiquer des problèmes côté serveur (comme des erreurs HTTP).

Request Count (Nombre de requêtes)
- Le graphique montre le nombre total de requêtes HTTP exécutées par les utilisateurs virtuels au fil du temps.
- Interprétation :
- Les trois endpoints testés sont affichés individuellement :
- /comments
- /posts
- /users
- Les requêtes augmentent avec la montée en charge et atteignent un pic lors du maximum d’utilisateurs actifs.
- Une diminution est observée lorsque les utilisateurs virtuels sont réduits.
- Les trois endpoints testés sont affichés individuellement :
- Utilisation :
- Permet d’évaluer si chaque endpoint reçoit la charge prévue.
- Une chute soudaine ou une absence de requêtes pourrait indiquer un problème (par exemple, des erreurs ou un endpoint non accessible).
- Permet d’évaluer si chaque endpoint reçoit la charge prévue.

Failed Request Count (Nombre de requêtes échouées)
- Le graphique montre le nombre de requêtes HTTP ayant échoué (par URL, statut HTTP et méthode) tout au long du test.
Interprétation :
- Ligne plate à zéro :
- Le fait que cette ligne reste à zéro indique qu’aucune requête HTTP n’a échoué pendant le test.
- Tous les endpoints testés (/comments, /posts, /users) ont retourné des réponses valides (statut HTTP 200).
Utilisation :
- Cela montre la fiabilité des endpoints sous la charge imposée par K6.
- Si des échecs apparaissaient, cela pourrait signaler :
- Des problèmes côté serveur (surcharge, erreurs applicatives).
- Des erreurs réseau ou de configuration (par exemple, des URL incorrectes).
Blocked Request Count (Nombre de requêtes bloquées)
- Le graphique montre la durée moyenne pendant laquelle les requêtes HTTP ont été bloquées avant d’être envoyées.
Interprétation :
- Augmentation au début de la montée en charge :
- Une augmentation est visible vers 17:30, ce qui correspond à la montée en charge des utilisateurs virtuels.
- Cela peut indiquer que le client K6 a temporairement mis en attente certaines requêtes en raison de :
- Temps d’établissement de connexions (TCP ou TLS).
- Latences dues à la gestion des threads.
- Diminution progressive :
- Une fois la montée en charge stabilisée, les requêtes bloquées sont quasiment inexistantes.
- Cela indique que le système testé et l’infrastructure réseau peuvent gérer la charge imposée sans retards significatifs.
Utilisation :
- Des requêtes bloquées prolongées peuvent signaler :
- Des problèmes côté client (temps de configuration des connexions).
- Des limitations réseau ou serveur qui ralentissent l’envoi des requêtes.

Request Sending Time (Temps d’envoi des requêtes)
- Le graphique montre le temps moyen nécessaire pour envoyer une requête HTTP au serveur.
- Interprétation :
- La valeur moyenne se situe autour de 100 à 200 µs (microsecondes).
- Une légère augmentation est visible lors de la montée en charge, mais le temps reste très faible.
- Vers la fin du test, le temps d’envoi diminue progressivement lorsque la charge baisse.
- Utilisation :
- Un temps d’envoi constant et faible indique que le client (K6) n’a pas rencontré de difficultés à transmettre les requêtes au serveur.
- Une augmentation marquée du temps d’envoi pourrait signaler des problèmes au niveau de la connectivité réseau ou de l’infrastructure de test.
Request Waiting Time (Temps d’attente des requêtes)
- Le graphique montre le temps moyen que K6 a attendu pour recevoir une réponse après avoir envoyé une requête.
- Interprétation :
- La valeur moyenne se situe autour de 30 ms, avec une stabilité notable tout au long du test.
- Une légère hausse est observée pendant la montée en charge (entre 17:30 et 17:45), probablement due à l’augmentation du nombre d’utilisateurs simultanés.
- La stabilité générale indique que le serveur a pu gérer la charge sans dégradation significative des performances.
- Utilisation :
- Un temps d’attente faible et constant montre que le serveur a répondu rapidement aux requêtes.
- Une augmentation progressive ou des pics soudains pourraient indiquer une surcharge du serveur ou des goulots d’étranglement (par exemple, une base de données lente).

Request Receiving Time (Temps de réception des requêtes)
- Le graphique montre le temps moyen nécessaire pour recevoir la réponse complète d’une requête HTTP après qu’elle a été envoyée.
Interprétation :
- Pic initial (10 ms) :
- Un pic est visible au début du test (aux alentours de 17:30), ce qui est typique lorsque les premiers utilisateurs virtuels commencent leurs interactions.
- Cela peut être lié à des latences initiales dues à la mise en cache ou à la montée en charge des serveurs.
- Stabilisation (5 ms) :
- Après ce pic, le temps de réception diminue et se stabilise autour de 5 ms, indiquant des réponses rapides et efficaces du serveur.
Utilisation :
- Un temps de réception stable et bas indique que le serveur peut répondre rapidement, même sous charge.
- Une augmentation progressive ou des pics constants pourraient signaler un problème côté serveur (latences élevées dues à des processus longs, surcharge réseau, ou tailles de réponses importantes).
Request TLS Handshaking (Établissement de la connexion TLS)
- Le graphique montre le temps moyen pris pour établir une connexion sécurisée TLS (Transport Layer Security).
Interprétation :
- Pic pendant la montée en charge (1,5 s) :
- Une augmentation soudaine est visible lors de la montée en charge (17:30), liée à l’augmentation rapide du nombre de connexions simultanées nécessitant une négociation TLS.
- Diminution rapide après stabilisation :
- Une fois la montée en charge terminée, le temps de handshake diminue et reste proche de 0 s, indiquant que le serveur peut gérer efficacement les connexions TLS après leur initialisation.
Utilisation :
- Un pic lors de la montée en charge est normal, car chaque utilisateur virtuel initialise une nouvelle connexion TLS.
- Si les temps de handshake restent élevés ou augmentent avec le temps, cela pourrait signaler des problèmes liés :
- À la capacité du serveur à gérer les connexions sécurisées.
- À des configurations TLS inefficaces (par exemple, certificats lourds ou configurations obsolètes).
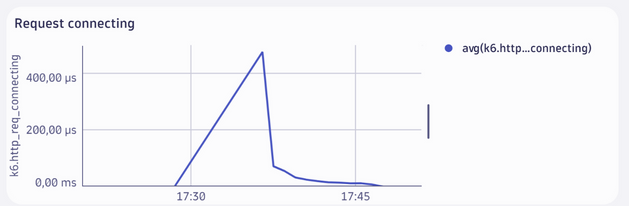
Request Connecting (Temps de connexion)
- Le graphique montre le temps moyen pris pour établir une connexion TCP avant d’envoyer une requête HTTP.
Interprétation :
- Pic initial (400 µs) :
- Un pic de temps de connexion est visible au début du test, vers 17:30. Cela correspond à la montée en charge où de nombreuses connexions TCP sont initialisées simultanément.
- Stabilisation à 0 µs :
- Après la montée en charge, le temps de connexion diminue rapidement à 0 µs, ce qui est attendu lorsque les connexions TCP sont déjà établies et réutilisées pour des requêtes ultérieures.